计算特征权重
所有的权重同样重要吗? 在这种情况下, 我们使用13个权重, 他们都贡献了模型. 然而, 这里的一个重要问题是, "我们如何知道哪些功能更重要?" 显然, 所有的特征对输出没有贡献. 如果我们想稍后丢弃其中的一些, 我们需要知道哪些功能不太重要. 我们在scikit-learn中有这个功能.
怎么做...?
- 让我们绘制特征的相对重要性. 将以下行添加到housing.py:
plot_feature_importances(
dt_regressor.feature_importances_,
'Decision Tree regressor',
housing_data.feature_names
)
plot_feature_importances(
ab_regressor.feature_importances_,
'AdaBoost regressor',
housing_data.feature_names
)
回归对象有一个可调用的feature_importances_方法,它给我们每个特性的权重.
- 我们实际上需要定义plot_feature_importances函数来绘制条形图
def plot_feature_importances(feature_importances, title, feature_names):
# 计算百分比
feature_importances = 100.0 * (feature_importances / max(feature_importances))
# 对值进行排序并将其翻转
index_sorted = np.flipud(np.argsort(feature_importances))
# 排列X刻度
pos = np.arange(index_sorted.shape[0]) + 0.5
# 绘制条形图
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
plt.xticks(pos, feature_names[index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
- 我们只需从feature_importances_方法获取值, 并缩放它, 使其范围在0到100之间. 如果运行前面的代码, 您将看到两个数字. 让我们看看我们将得到一个基于决策树的回归, 如下图所示:
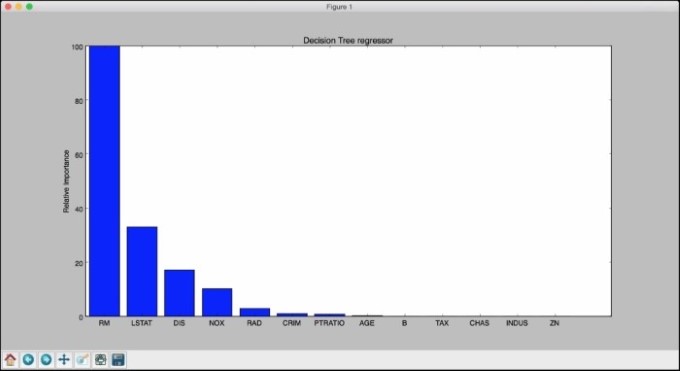
- 因此, 决策树回归者说最重要的特征是RM. 让我们来看看AdaBoost在下图中说的内容:
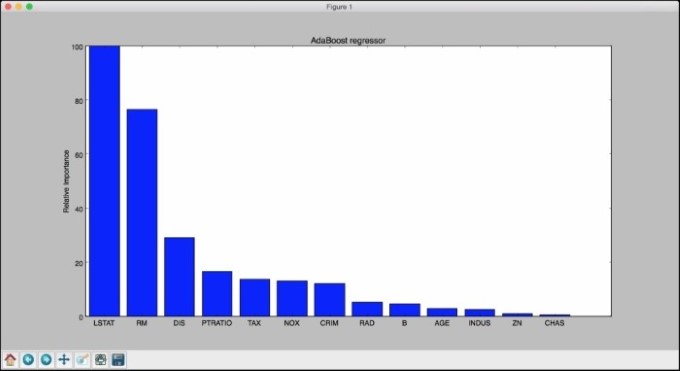
根据AdaBoost, 最重要的特性是LSTAT. 在现实中, 如果你对这些数据构建各种回归, 你会发现最重要的特性实际上是LSTAT. 这显示了使用AdaBoost和基于决策树的回归的优势.