使用支持向量机(SVM)构建线性分类器
SVM是用于构建分类器和回归的监督学习模型. SVM通过求解数学方程组来找到两组点之间的最佳分离边界. 如果你不熟悉SVM, 里有一些很好的教程(英文):
- http://web.mit.edu/zoya/www/SVM.pdf
- http://www.support-vector.net/icml-tutorial.pdf
- http://www.svms.org/tutorials/Berwick2003.pdf
接下来看看如何构建基于SVM的线性分类器.
准备
让我们可视化我们的数据以了解手头的问题. 我们将使用已经提供给您的svm.py作为参考. 在我们构建SVM之前, 让我们来了解我们的数据. 我们将使用已经提供给您的data_multivar.txt文件.
让我们看看如何可视化数据。
创建一个新的Python文件并添加以下行:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import utilities
# Load input data
input_file = 'data_multivar.txt'
X, y = utilities.load_data(input_file)
def load_data(input_file):
X = []
y = []
with open(input_file, 'r') as f:
for line in f.readlines():
data = [float(x) for x in line.split(',')]
X.append(data[:-1])
y.append(data[-1])
X = np.array(X)
y = np.array(y)
return X, y
# Separate the data into classes based on 'y'
class_0 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
class_1 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
plt.figure()
plt.scatter(
class_0[:, 0],
class_0[:, 1],
facecolors='black',
edgecolors='black',
marker='s'
)
plt.scatter(
class_1[:, 0],
class_1[:, 1],
facecolors='None',
edgecolors='black',
marker='s'
)
plt.title('Input data')
plt.show()
显示结果如下:
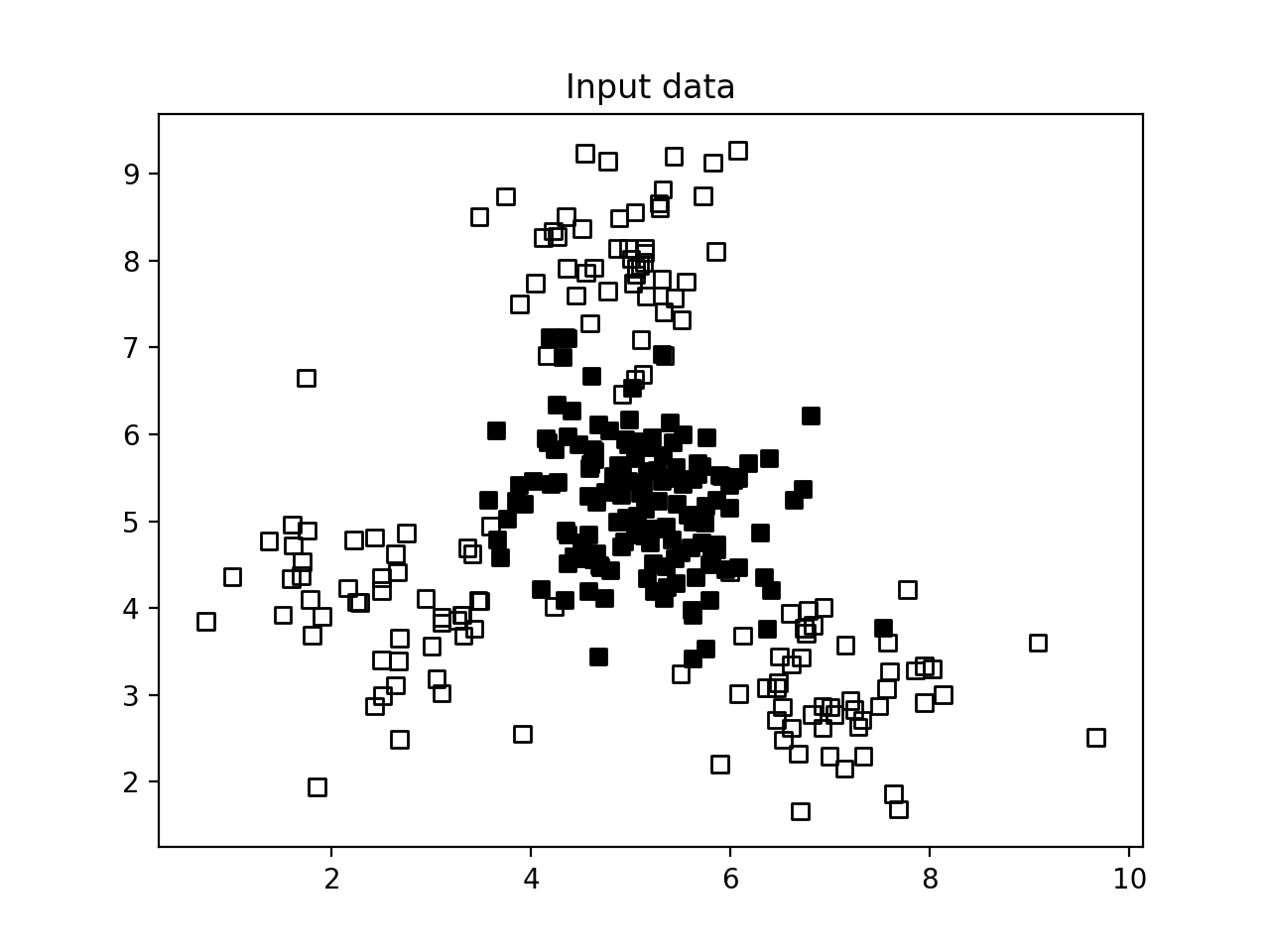 上图包括两种类型的点 - 实心方形和空白方形. 在机器学习中, 我们说我们的数据包括两个类. 我们的目标是建立一个模型, 可以将实心方块与空方块分开.
上图包括两种类型的点 - 实心方形和空白方形. 在机器学习中, 我们说我们的数据包括两个类. 我们的目标是建立一个模型, 可以将实心方块与空方块分开.
怎么做...?
- 我们需要将数据集分成训练和测试数据集. 将以下行添加到同一个Python文件:
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
random_state=5
)
- 让我们使用线性内核初始化SVM对象. 如果你不知道什么内核, 你可以查看http://www.eric-kim.net/eric-kim-net/posts/1/kernel_trick.html. 将以下行添加到文件:
params = {'kernel': 'linear'}
# params = {'kernel': 'poly', 'degree': 3}
# params = {'kernel': 'rbf'}
classifier = SVC(**params)
- 然后训练模型:
classifier.fit(X_train, y_train)
- 做图并显示:
utilities.plot_classifier(classifier, X_train, y_train, 'Training dataset')
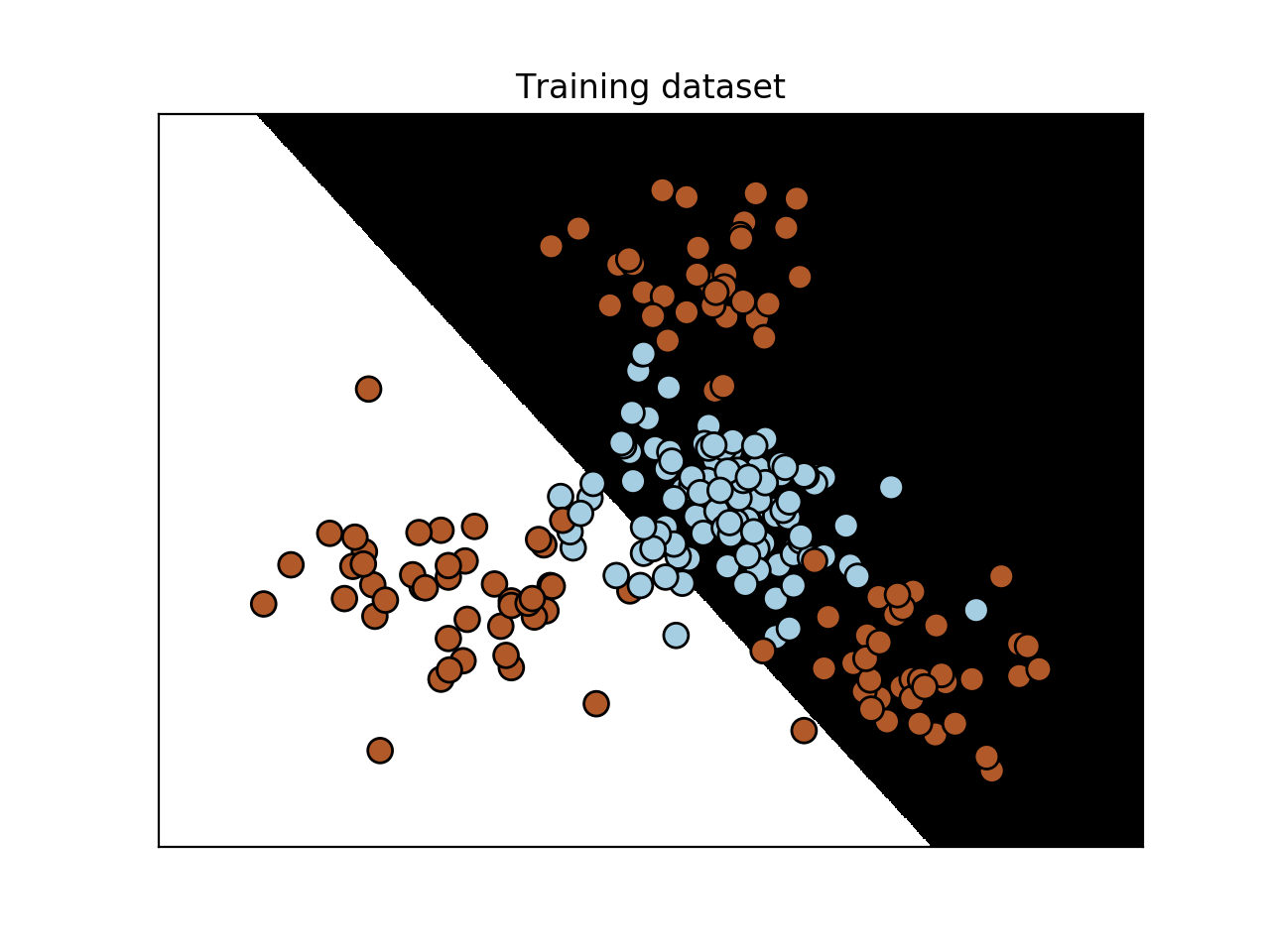
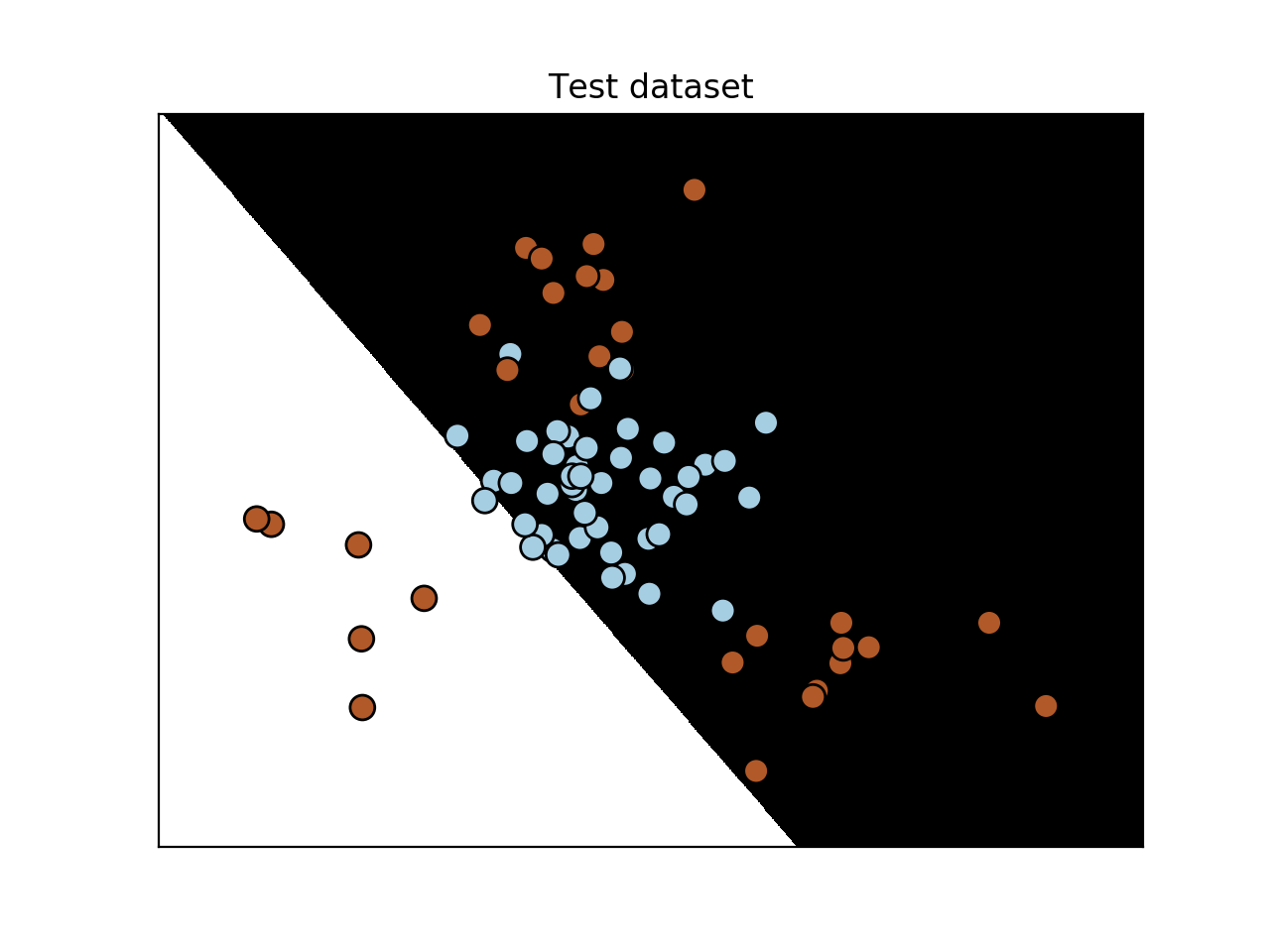
- 验证测试数据:
y_test_pred = classifier.predict(X_test)
utilities.plot_classifier(classifier, X_test, y_test, 'Test dataset')
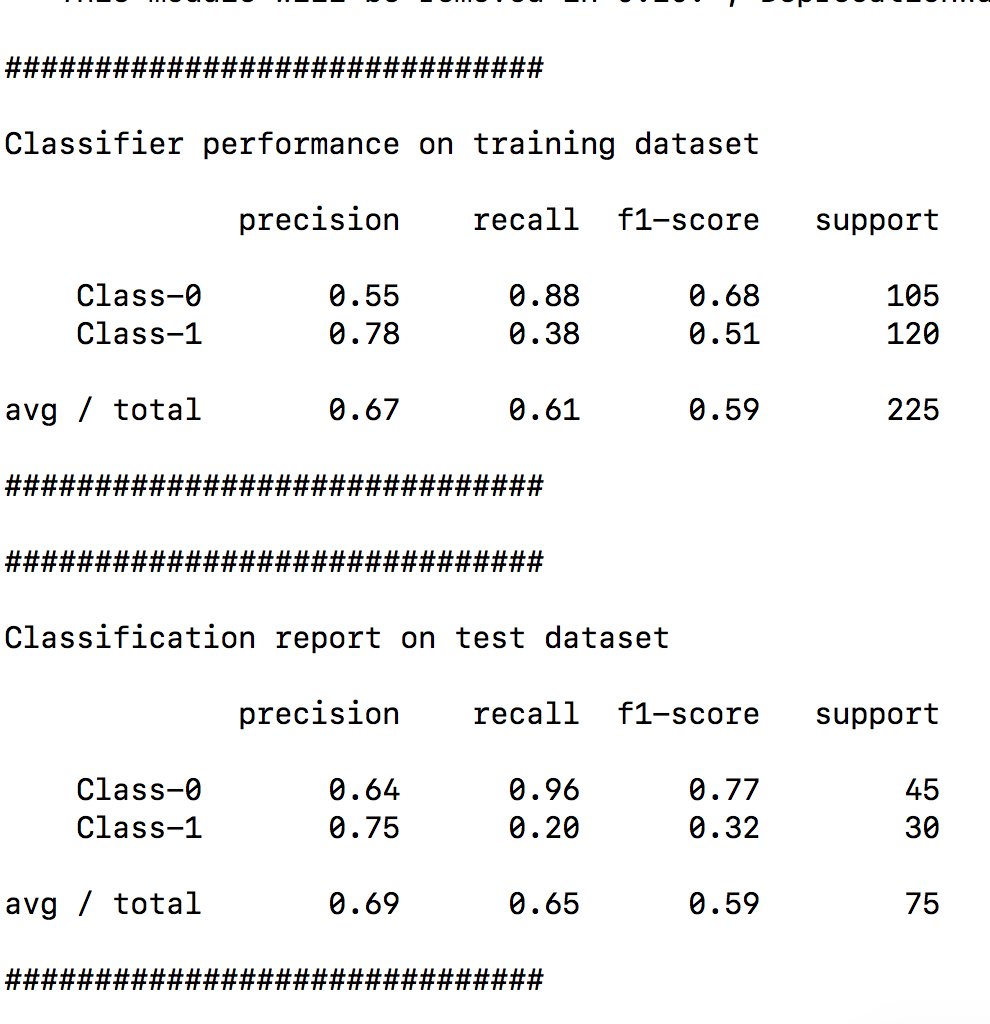
- 最后分别计算训练数据集和测试数据集的精确率:
target_names = ['Class-' + str(int(i)) for i in set(y)]
print ("\n" + "#" * 30)
print ("\nClassifier performance on training dataset\n")
print (classification_report(
y_train,
classifier.predict(X_train),
target_names=target_names)
)
print ("#" * 30 + "\n")
print ("#" * 30)
print ("\nClassification report on test dataset\n")
print (classification_report(y_test, y_test_pred, target_names=target_names))
print ("#" * 30 + "\n")
从我们可视化数据的图中, 我们可以看到实心方块完全被空方块包围. 这意味着数据不是线性可分的. 我们不能画出一条漂亮的直线来分隔两组点! 因此, 我们需要一个非线性分类器来分离这些数据点.