如前一章所讨论的, 超参数在确定分类器的性能中是重要的. 让我们来看看如何为SVM提取最优的超参数.
怎么做...?
- 完整的代码在已经提供给你的perform_grid_search.py文件中给出. 我们在这里只讨论食谱的核心部分. 我们将在这里使用交叉验证, 我们在之前的食谱中介绍. 加载数据并将其拆分为训练和测试数据集后,请将以下内容添加到文件中:
# Set the parameters by cross-validation
parameter_grid = [
{
'kernel': ['linear'],
'C': [1, 10, 50, 600]
},
{
'kernel': ['poly'],
'degree': [2, 3]
},
{
'kernel': ['rbf'],
'gamma': [0.01, 0.001],
'C': [1, 10, 50, 600]
},
]
- 让我们定义我们要使用的指标
metrics = ['precision', 'recall_weighted']
- 让我们开始搜索每个度量的最佳超参数
for metric in metrics:
print ("\n#### Searching optimal hyperparameters for", metric)
classifier = GridSearchCV(
svm.SVC(C=1),
parameter_grid,
cv=5,
scoring=metric
)
classifier.fit(X_train, y_train)
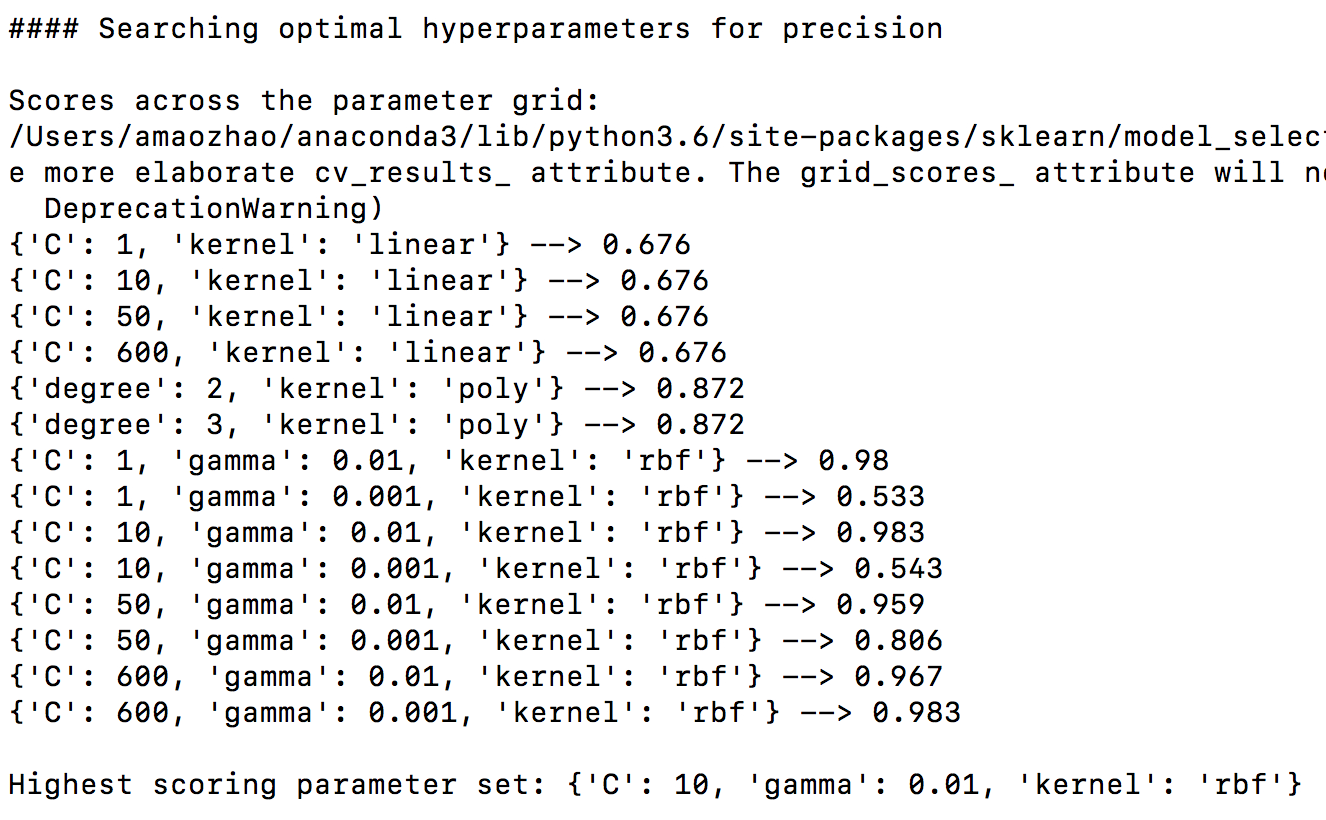
print ("\nScores across the parameter grid:")
for params, avg_score, _ in classifier.grid_scores_:
print (params, '-->', round(avg_score, 3))
print ("\nHighest scoring parameter set:", classifier.best_params_)
y_true, y_pred = y_test, classifier.predict(X_test)
print ("\nFull performance report:\n")
print (classification_report(y_true, y_pred))
- 结果如下: