解决类不平衡
到目前为止, 我们处理的问题是我们在所有类中有相似数量的数据点. 在现实世界中, 我们可能无法以这种有序的方式获取数据. 有时, 一个类中的数据点的数量比其他类中的数据点的数量多得多. 如果发生这种情况, 那么分类器往往会产生偏差. 边界将不会反映您的数据的真实性质, 因为两个类之间的数据点的数量有很大的差异. 因此, 重要的是解决这种差异并中和它, 使我们的分类器保持公正.
怎么做...?
- 导入数据
input_file = 'data_multivar_imbalance.txt'
X, y = utilities.load_data(input_file)
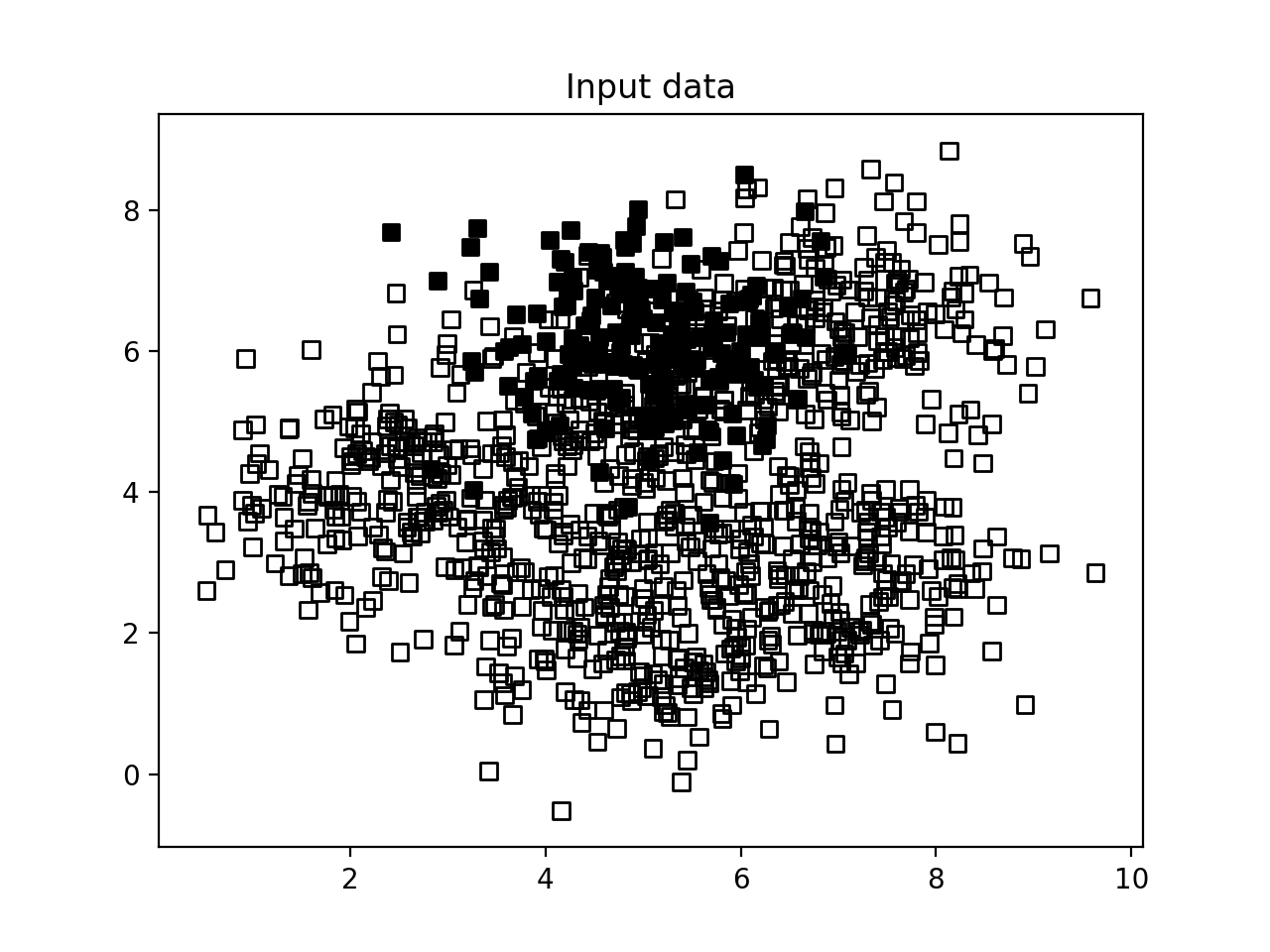
- 数据可视化, 代码可以在svm_imbalance.py文件中找到:
- 让我们使用线性内核构建SVM. 代码与上一个配方中的代码相同. 如果你运行它, 你会看到下图:
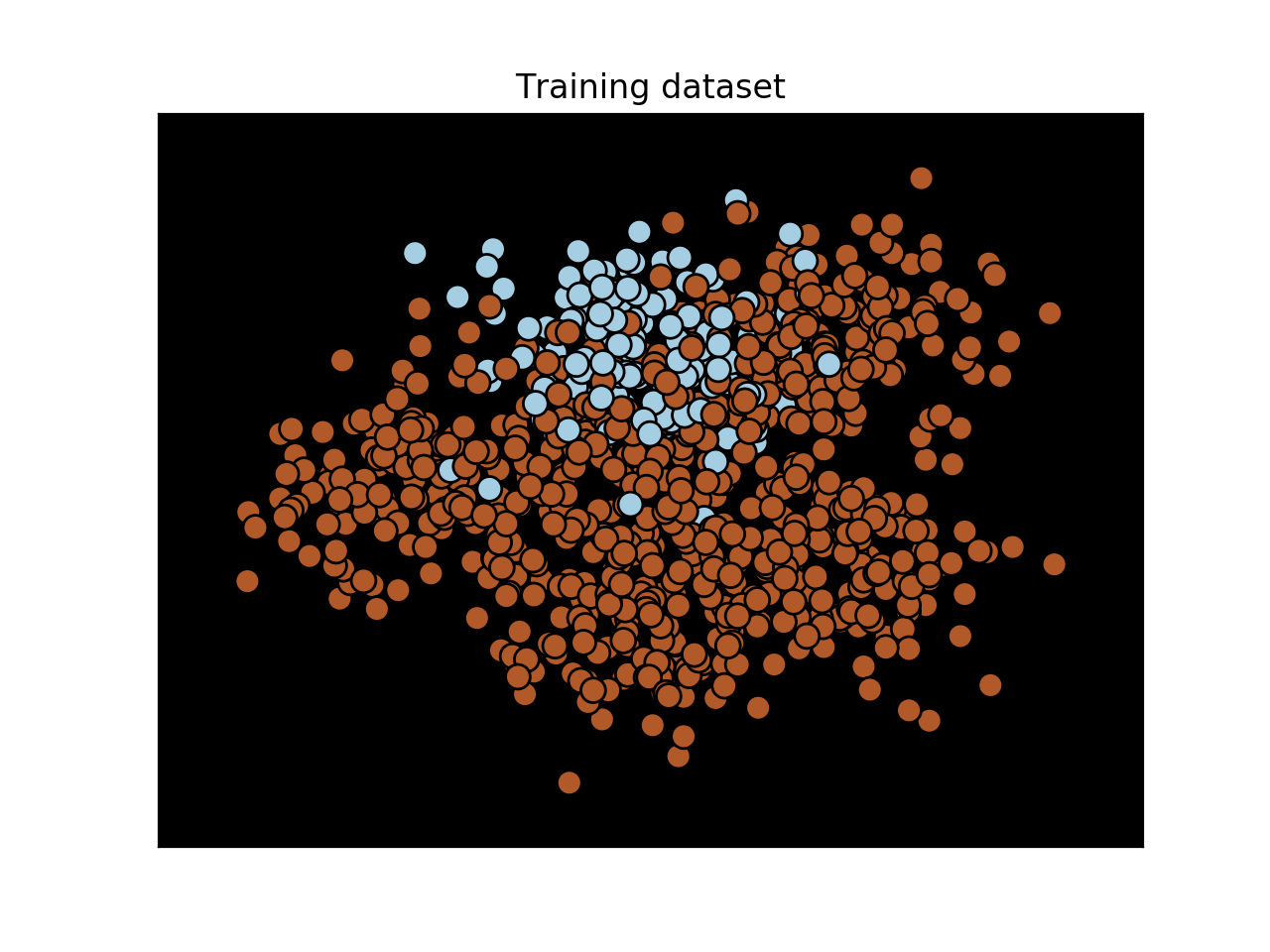
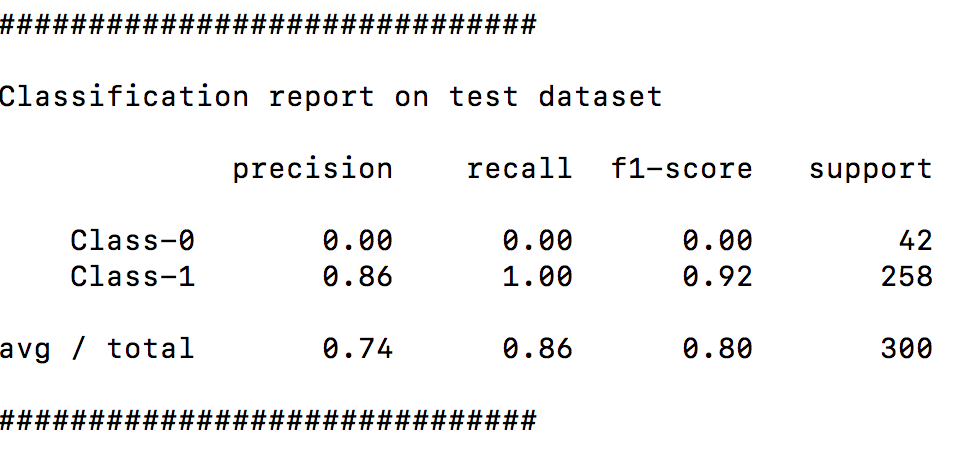
- 你可能想知道为什么这里没有边界! 嗯, 这是因为分类器不能分离这两个类, 导致0级的0%的准确性. 您还将在终端上看到打印的分类报告, 如以下屏幕截图所示:
- 让我们继续解决这个问题! 在Python文件中, 搜索以下行:
params = {'kernel': 'linear'}
# 替换为
params = {'kernel': 'linear', 'class_weight': 'balanced'}
# class_weight参数将计算每个类中的数据点的数量以调整权重, 使得不平衡不会不利地影响性能
- 运行代码得到以下图形:
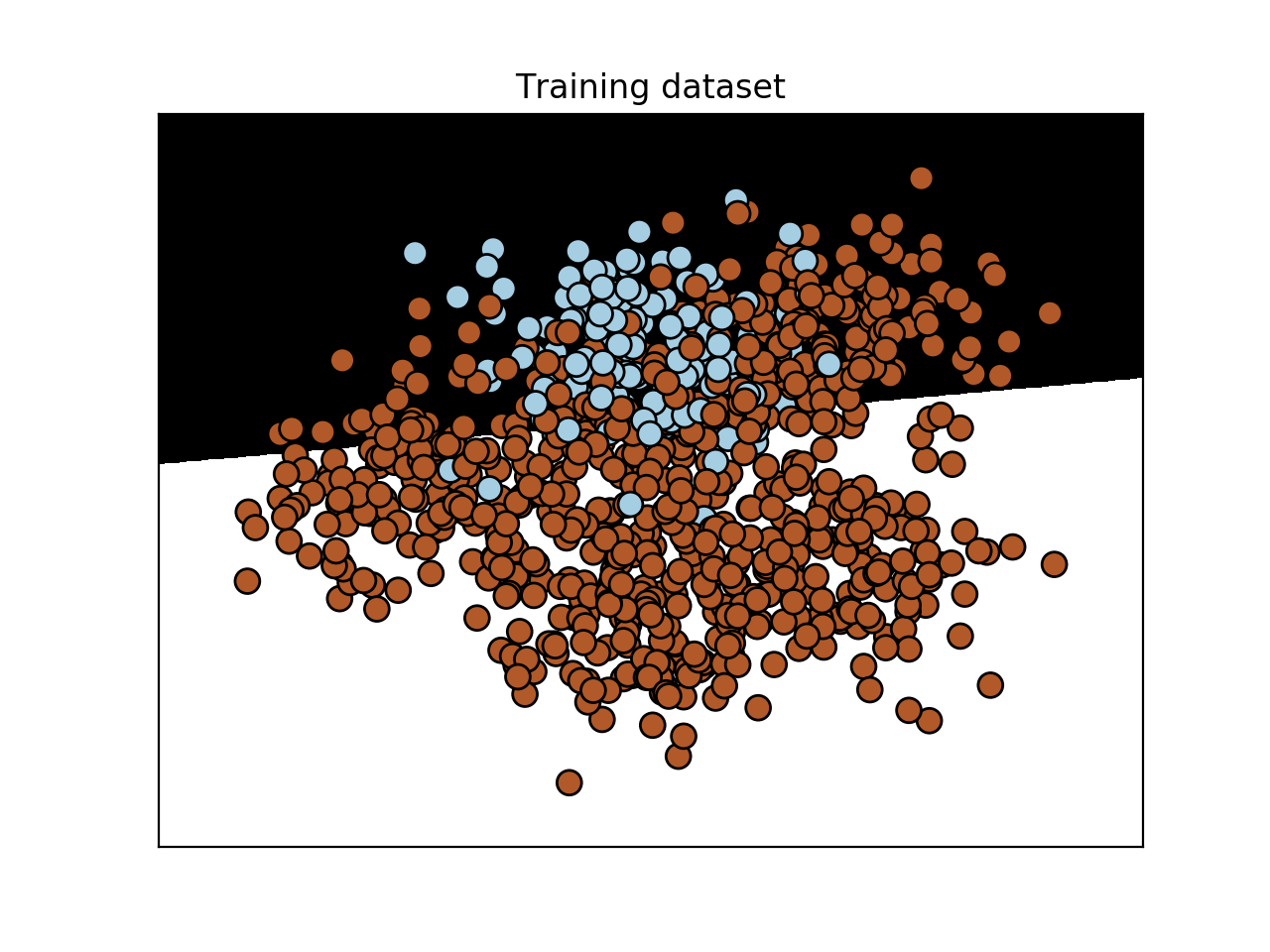
- 报告如下:
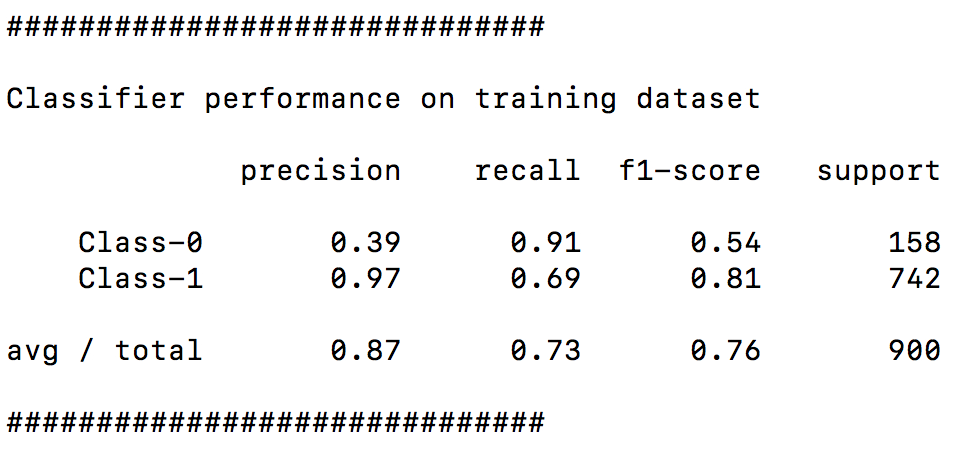
我们可以看到, 类-0现在检测到非零的百分比精度.