创建贝叶斯分类器
朴素贝叶斯分类器是一种监督学习分类器, 它使用贝叶斯定理来建立模型. 让我们继续构建一个朴素贝叶斯分类器.
- 我们将使用提供给您的naive_bayes.py作为参考, 让我们导入几个模块
from sklearn.naive_bayes import GaussianNB
from logistic_regression import plot_classifier
- 您获得了一个data_multivar.txt文件. 这里包含我们将在这里使用的数据. 它在每行中包含逗号分隔的数值数据. 让我们从这个文件加载数据:
input_file = 'data_multivar.txt'
X = []
y = []
with open(input_file, 'br') as f:
for line in f.readlines():
data = [float(x) for x in line.split(',')]
X.append(data[:-1])
y.append(data[-1])
X = np.array(X)
y = np.array(y)
# 现在就载入了数据到X和y
- 创建贝叶斯分类器
classifier_gaussiannb = GaussianNB()
# GaussionNB 表示高斯贝叶斯
classifier_gaussiannb.fit(X, y)
y_pred = classifier_gaussiannb.predict(X)
- 计算分类器准确率
accuracy = 100.0 * (y == y_pred).sum() / X.shape[0]
print ("Accuracy of the classifier =", round(accuracy, 2), "%")
- 绘制图形
plot_classifier(classifier_gaussiannb, X, y)
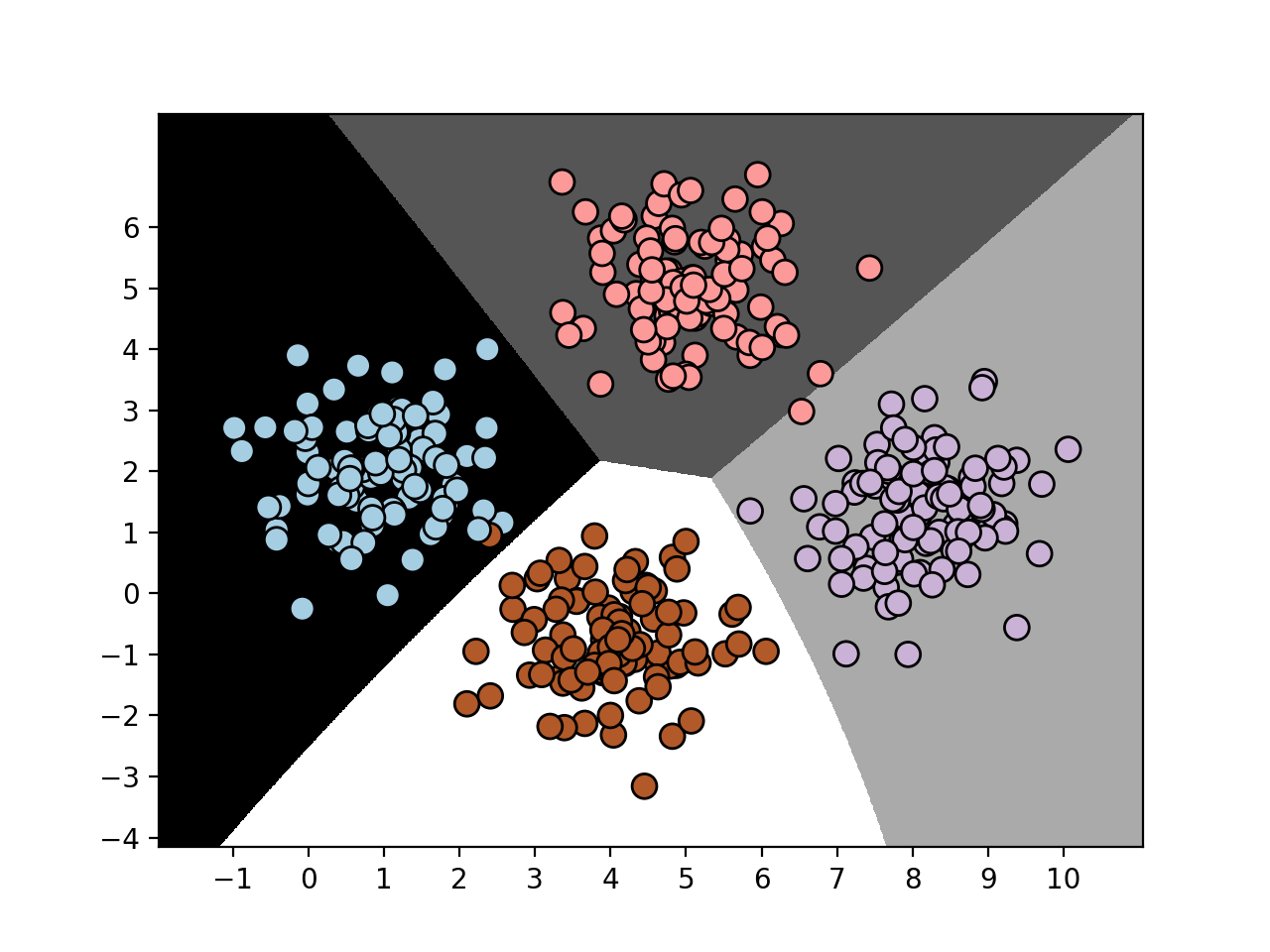 在这里, 边界没有限制是线性的. 在前面的例子中, 我们用完所有的数据进行训练. 机器学习的一个好的做法是具有用于训练和测试的非重叠数据. 理想情况下, 我们需要一些未使用的数据进行测试, 以便我们能够准确估计模型对未知数据的执行情况. 在scikit-learn中有一个规定处理这个很好. 如下一章所示.
在这里, 边界没有限制是线性的. 在前面的例子中, 我们用完所有的数据进行训练. 机器学习的一个好的做法是具有用于训练和测试的非重叠数据. 理想情况下, 我们需要一些未使用的数据进行测试, 以便我们能够准确估计模型对未知数据的执行情况. 在scikit-learn中有一个规定处理这个很好. 如下一章所示.