k-means算法是最流行的聚类算法之一. 该算法用于使用数据的各种属性将输入数据划分为k个子组. 使用优化技术实现分组, 我们尝试将数据点之间的距离和集群的相应中心之间的距离的平方和最小化. 如果您需要快速复习, 可以在http://www.onmyphd.com/?p=k-means.clustering&ckattempt=1上了解更多有关k-means的信息.
怎么做...?
- 该配方的完整代码在已提供给您的kmeans.py文件中给出. 我们来看看它是如何构建的. 创建一个新的Python文件, 并导入以下软件包
import numpy as np
import matplotlib.pyplot as plt
# from sklearn import metrics
from sklearn.cluster import KMeans
import utilities
- 我们加载输入数据并定义集群数. 我们将使用已经提供给您的data_multivar.txt文件
data = utilities.load_data('data_multivar.txt')
num_clusters = 4
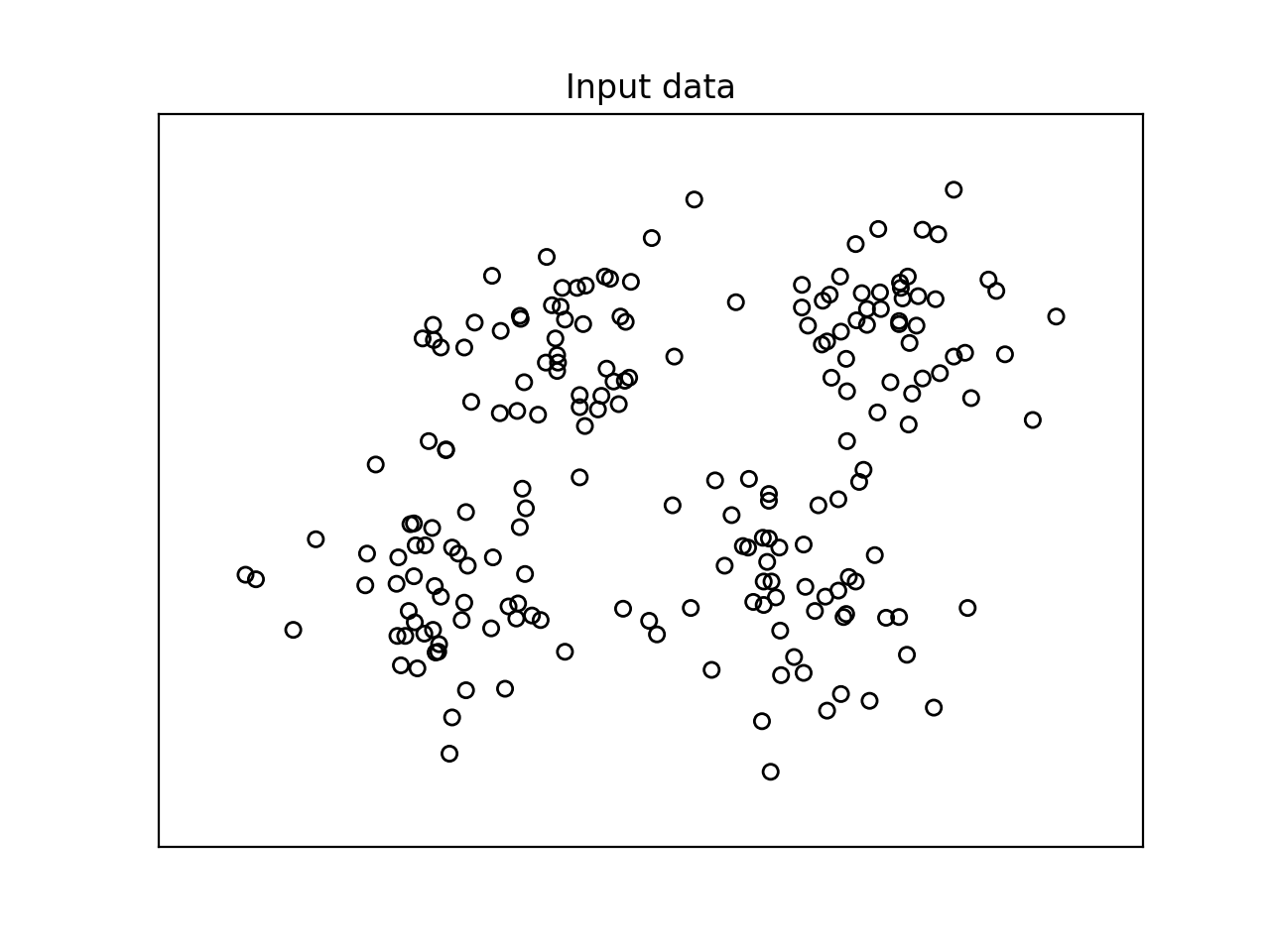
- 我们需要看看输入数据的样子. 让我们继续添加以下代码行到Python文件:
# Plot data
plt.figure()
plt.scatter(
data[:, 0],
data[:, 1],
marker='o',
facecolors='none',
edgecolors='k',
s=30
)
x_min, x_max = min(data[:, 0]) - 1, max(data[:, 0]) + 1
y_min, y_max = min(data[:, 1]) - 1, max(data[:, 1]) + 1
plt.title('Input data')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
运行以上代码可以看到如下图形:
- 我们现在准备训练模型了. 让我们初始化k-means对象并进行训练:
# Train the model
kmeans = KMeans(init='k-means++', n_clusters=num_clusters, n_init=10)
kmeans.fit(data)
- 现在数据被训练了, 我们需要可视化的边界. 让我们继续添加以下代码行到Python文件:
# Step size of the mesh
step_size = 0.01
# Plot the boundaries
x_min, x_max = min(data[:, 0]) - 1, max(data[:, 0]) + 1
y_min, y_max = min(data[:, 1]) - 1, max(data[:, 1]) + 1
x_values, y_values = np.meshgrid(
np.arange(x_min, x_max, step_size), np.arange(y_min, y_max, step_size))
# Predict labels for all points in the mesh
predicted_labels = kmeans.predict(np.c_[x_values.ravel(), y_values.ravel()])
# Plot the results
predicted_labels = predicted_labels.reshape(x_values.shape)
- 我们只是通过一个网格来评估模型. 我们来绘制这些结果来查看边界:
# Plot the results
predicted_labels = predicted_labels.reshape(x_values.shape)
plt.figure()
plt.clf()
plt.imshow(
predicted_labels,
interpolation='nearest',
extent=(
x_values.min(),
x_values.max(),
y_values.min(),
y_values.max()
),
cmap=plt.cm.Paired,
aspect='auto',
origin='lower'
)
plt.scatter(
data[:, 0],
data[:, 1],
marker='o',
facecolors='none',
edgecolors='k',
s=30
)
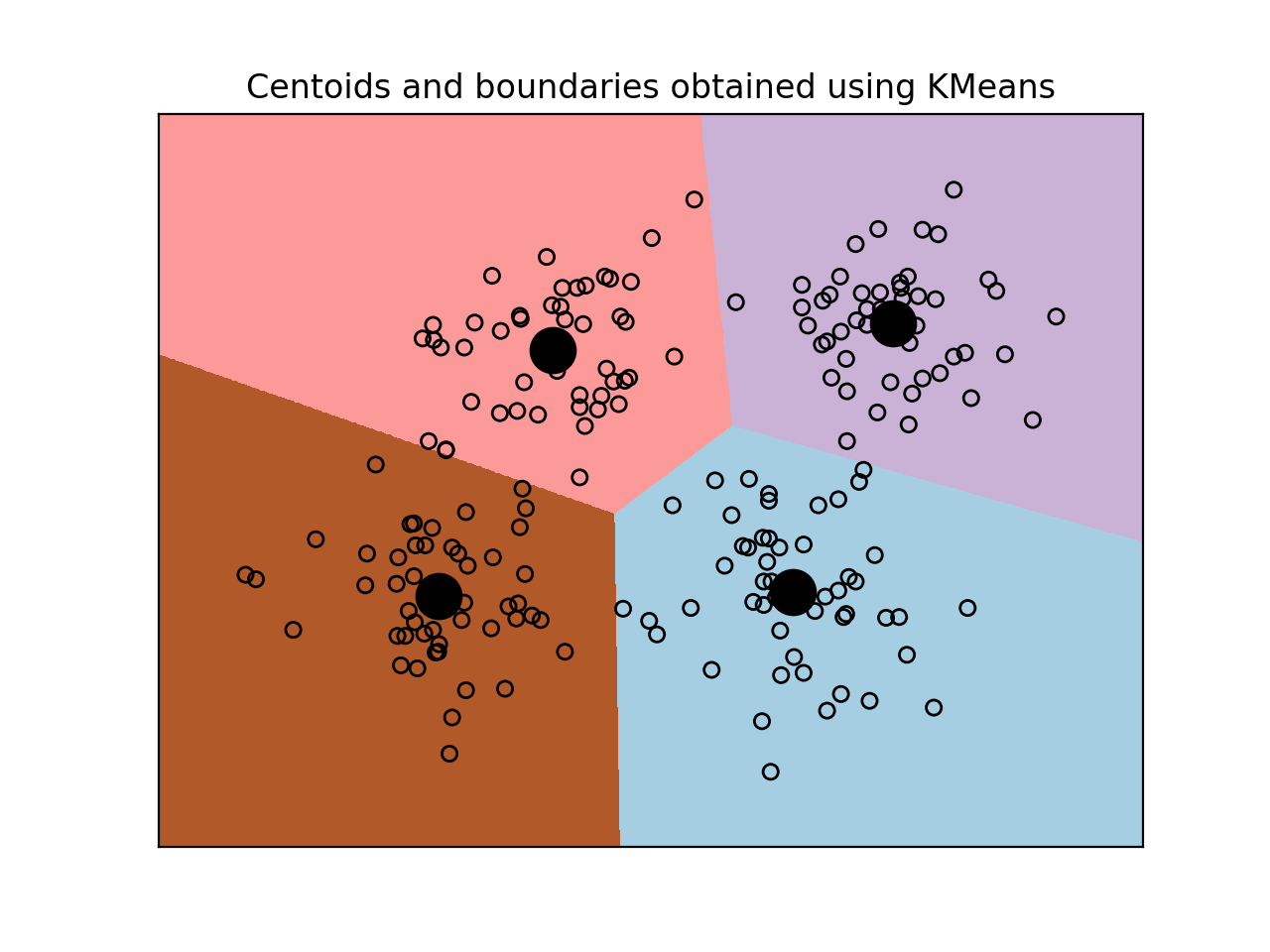
- 我们把中心叠加在它上面:
centroids = kmeans.cluster_centers_
plt.scatter(
centroids[:, 0],
centroids[:, 1],
marker='o',
s=200,
linewidths=3,
color='k',
zorder=10,
facecolors='black'
)
x_min, x_max = min(data[:, 0]) - 1, max(data[:, 0]) + 1
y_min, y_max = min(data[:, 1]) - 1, max(data[:, 1]) + 1
plt.title('Centoids and boundaries obtained using KMeans')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
运行以上代码显示图形如下: