到目前为止, 我们构建了不同的聚类算法, 但没有测量它们的性能. 在监督学习中, 我们将预测值与原始标签进行比较, 以计算其准确性. 在无监督的学习中, 我们没有任何标签. 因此, 我们需要一种方法来衡量我们的算法的性能.
测量聚类算法的一个好方法是通过查看集群的分离情况. 集群是否分离好? 群集中的数据点是否足够紧密? 我们需要一个量度这个行为的指标. 我们将使用一个称为"剪影系数"得分的指标. 为每个数据点定义此分数. 该系数定义如下:
score =(x-y)/ max(x,y)
这里, x是当前数据点与同一簇中所有其他数据点之间的平均距离; y是当前数据点与下一个最近聚类中所有数据点之间的平均距离.
怎么做...?
- 该食谱的完整代码已提供给您的performance.py文件中给出. 我们来看看它是如何构建的. 创建一个新的Python文件, 并导入以下软件包:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.cluster import KMeans
import utilities
- 导入文件data_perf.txt中的数据集:
data = utilities.load_data('data_perf.txt')
- 为了确定最佳聚类数, 让我们设置一个范围值,看看它在哪里峰值:
for i in range_values:
# Train the model
kmeans = KMeans(init='k-means++', n_clusters=i, n_init=10)
kmeans.fit(data)
score = metrics.silhouette_score(
data,
kmeans.labels_,
metric='euclidean',
sample_size=len(data)
)
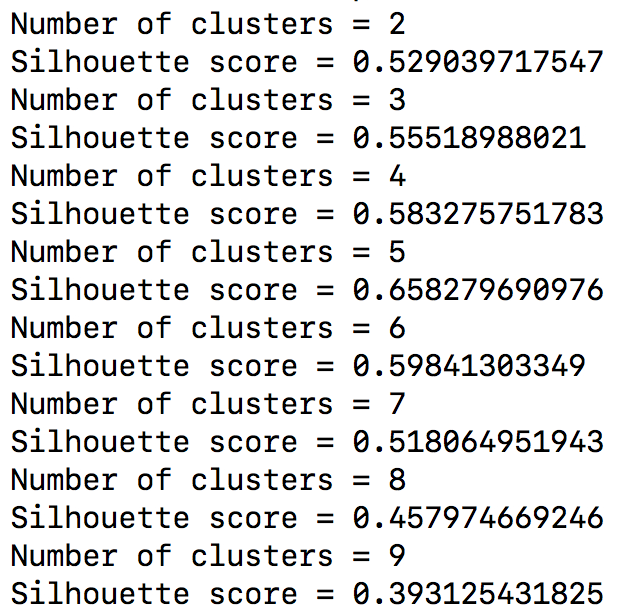
print ("Number of clusters =", i)
print ("Silhouette score =", score)
scores.append(score)
- 我们来绘制图表, 看看它在哪里达到峰值:
# Plot scores
plt.figure()
plt.bar(range_values, scores, width=0.6, color='k', align='center')
plt.title('Silhouette score vs number of clusters')
# Plot data
plt.figure()
plt.scatter(data[:, 0], data[:, 1], color='k',
s=30, marker='o', facecolors='none')
x_min, x_max = min(data[:, 0]) - 1, max(data[:, 0]) + 1
y_min, y_max = min(data[:, 1]) - 1, max(data[:, 1]) + 1
plt.title('Input data')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
- 运行代码, 结果如下图:
- 柱状图如下:
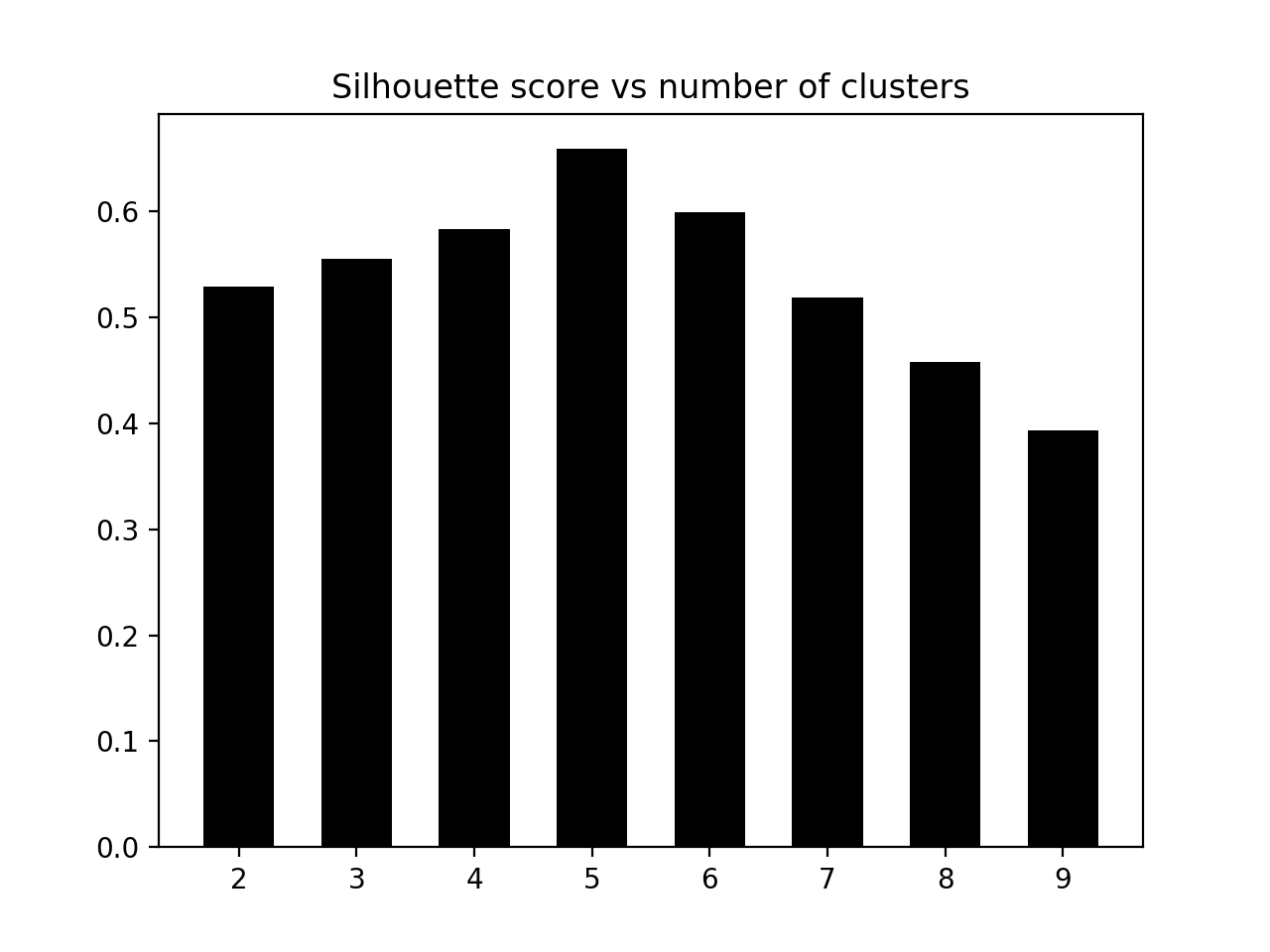
- 根据这些分数, 最好的配置是五个集群. 我们来看看数据的实际情况:
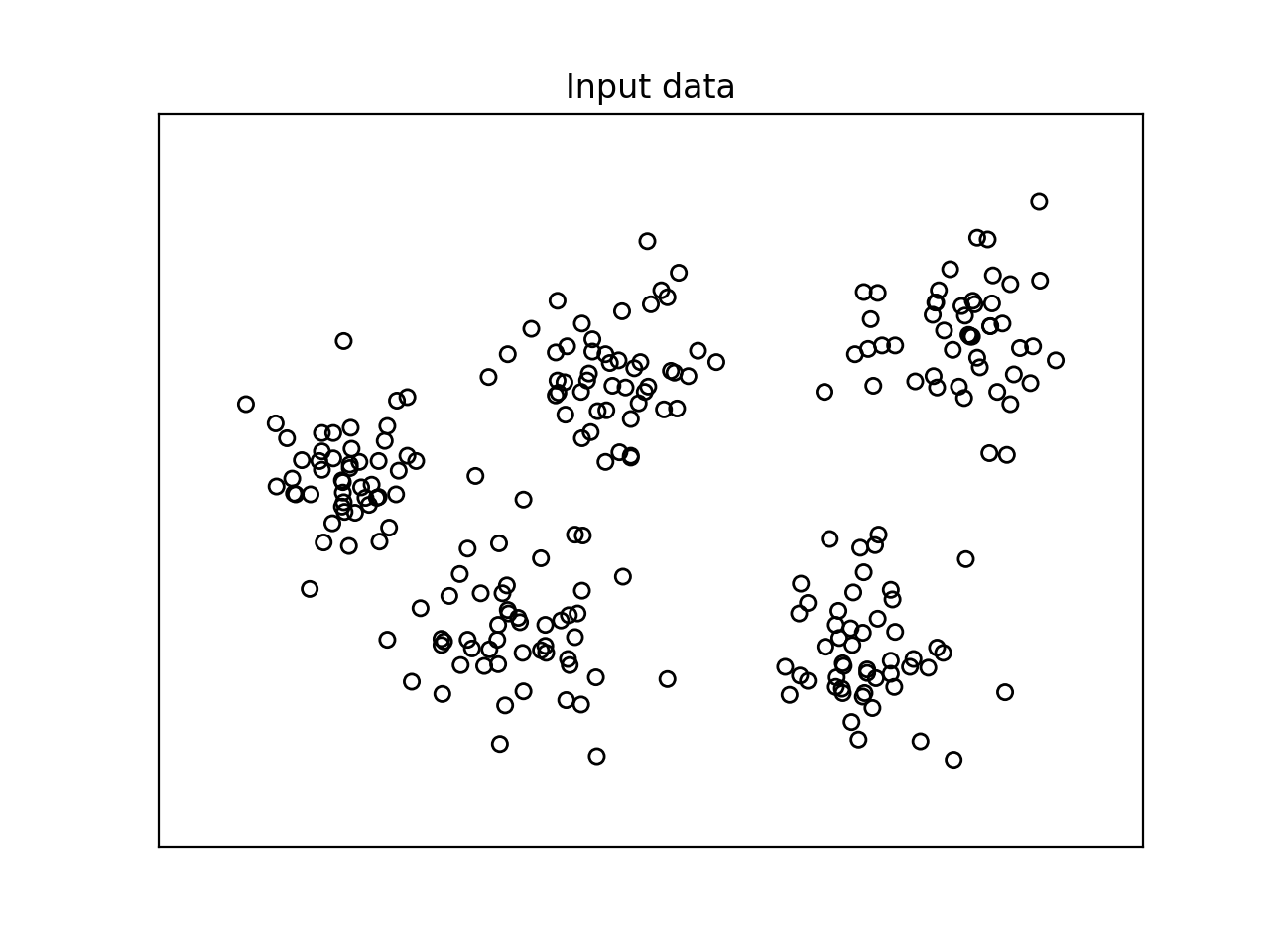
我们可以直观地确认数据其实有五个类. 我们仅仅举了一个包含五个不同集群的小数据集的例子. 当处理包含不能容易地可视化的高维数据的巨大数据集时, 此方法变得非常有用.