现在我们构建了推荐引擎的所有不同部分, 我们已经准备好生成电影建议. 我们将使用我们在之前配方中构建的所有功能来构建电影推荐引擎. 让我们看看如何建立它.
怎么做...?
- 创建文件并导入需要的包:
import json
import numpy as np
from pearson_score import pearson_score
- 我们将定义一个函数来为给定的用户生成电影推荐. 第一步是检查用户是否存在于数据集中:
# Generate recommendations for a given user
def generate_recommendations(dataset, user):
if user not in dataset:
raise TypeError('User ' + user + ' not present in the dataset')
total_scores = {}
similarity_sums = {}
for u in [x for x in dataset if x != user]:
similarity_score = pearson_score(dataset, user, u)
if similarity_score <= 0:
continue
for item in [
x for x in dataset[u]
if x not in dataset[user] or dataset[user][x] == 0]:
total_scores.update({item: dataset[u][item] * similarity_score})
similarity_sums.update({item: similarity_score})
if len(total_scores) == 0:
return ['No recommendations possible']
# Create the normalized list
movie_ranks = np.array(
[
[total / similarity_sums[item], item]
for item, total in total_scores.items()
]
)
# Sort in decreasing order based on the first column
movie_ranks = movie_ranks[np.argsort(movie_ranks[:, 0])[::-1]]
# Extract the recommended movies
recommendations = [movie for _, movie in movie_ranks]
return recommendations
- 我们来定义主函数并加载数据集
if __name__ == '__main__':
data_file = 'movie_ratings.json'
with open(data_file, 'r') as f:
data = json.loads(f.read())
user = 'Michael Henry'
print ("Recommendations for " + user + ":")
movies = generate_recommendations(data, user)
for i, movie in enumerate(movies):
print (str(i + 1) + '. ' + movie)
user = 'John Carson'
print ("Recommendations for " + user + ":")
movies = generate_recommendations(data, user)
for i, movie in enumerate(movies):
print (str(i + 1) + '. ' + movie)
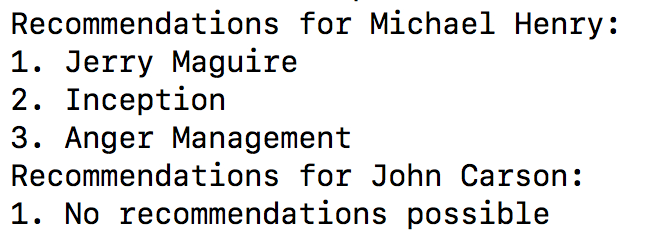
- 运行结果如下: