无监督学习的主要应用之一是市场细分. 这是当我们没有标签的数据可用的所有时间, 但重要的是分割市场, 以便人们可以针对单个组. 这在广告, 库存管理, 实施分销策略, 大众媒体等方面非常有用. 让我们继续, 将无监督的学习应用于一个这样的情况, 看看它是如何起作用的.
我们将与批发商和客户打交道. 我们将使用https://archive.ics.uci.edu/ml/datasets/Wholesale+customers上提供的数据. 电子表格包含有关客户对不同类型项目的消费的数据, 我们的目标是找到集群, 以便优化其销售和分配策略.
怎么做...?
- 该配方的完整代码在customer_segmentation.py文件中给出. 我们来看看它是如何构建的. 创建一个新的Python文件,并导入以下软件包:
import csv
import numpy as np
# from sklearn import cluster, covariance, manifold
from sklearn.cluster import MeanShift, estimate_bandwidth
import matplotlib.pyplot as plt
- 从wholesale.csv导入数据:
# Load data from input file
input_file = 'wholesale.csv'
file_reader = csv.reader(open(input_file, 'r'), delimiter=',')
X = []
for count, row in enumerate(file_reader):
if not count:
names = row[2:]
continue
X.append([float(x) for x in row[2:]])
# Input data as numpy array
X = np.array(X)
- 让我们建立一个平均偏移模型, 就像我们在之前的一个食谱中所做的那样:
# Estimating the bandwidth
bandwidth = estimate_bandwidth(X, quantile=0.8, n_samples=len(X))
# Compute clustering with MeanShift
meanshift_estimator = MeanShift(bandwidth=bandwidth, bin_seeding=True)
meanshift_estimator.fit(X)
labels = meanshift_estimator.labels_
centroids = meanshift_estimator.cluster_centers_
num_clusters = len(np.unique(labels))
print ("Number of clusters in input data =", num_clusters)
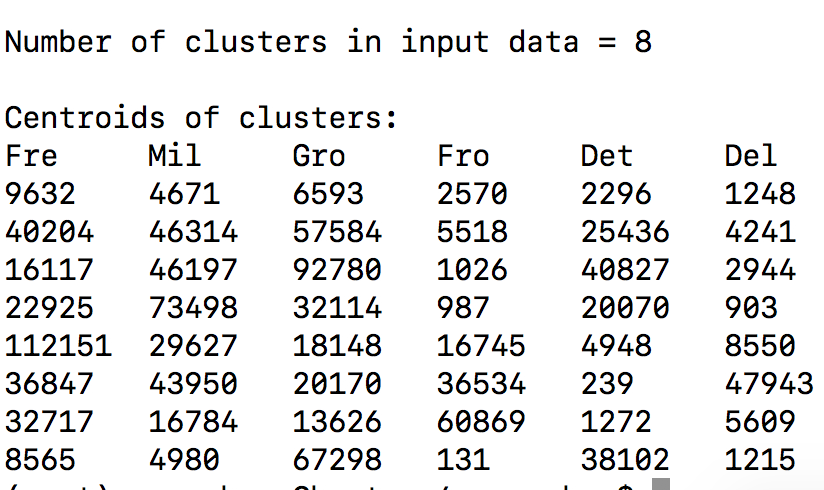
- 我们打印我们获得的聚类的质心, 如下所示:
print ("Centroids of clusters:")
print ('\t'.join([name[:3] for name in names]))
for centroid in centroids:
print ('\t'.join([str(int(x)) for x in centroid]))
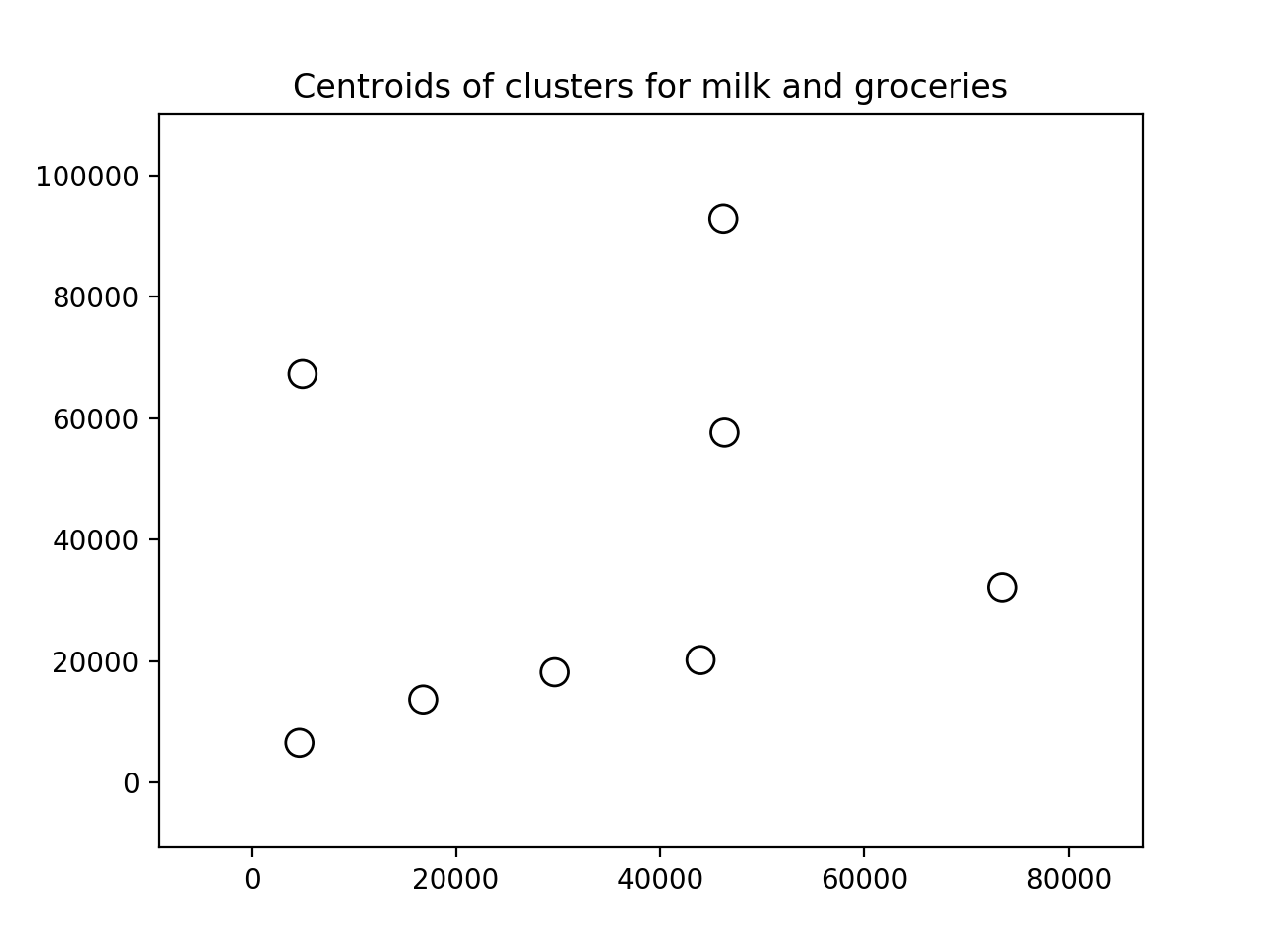
- 可视化特征输出:
################
# Visualizing data
centroids_milk_groceries = centroids[:, 1:3]
# Plot the nodes using the coordinates of our centroids_milk_groceries
plt.figure()
plt.scatter(centroids_milk_groceries[:, 0], centroids_milk_groceries[:, 1],
s=100, edgecolors='k', facecolors='none')
offset = 0.2
plt.xlim(
centroids_milk_groceries[:, 0].min() -
offset * centroids_milk_groceries[:, 0].ptp(),
centroids_milk_groceries[:, 0].max() +
offset * centroids_milk_groceries[:, 0].ptp(),
)
plt.ylim(
centroids_milk_groceries[:, 1].min() -
offset * centroids_milk_groceries[:, 1].ptp(),
centroids_milk_groceries[:, 1].max() +
offset * centroids_milk_groceries[:, 1].ptp()
)
plt.title('Centroids of clusters for milk and groceries')
plt.show()
- 输出结果如下:
- 您将获得以下图像, 描述牛奶和杂货的特征, 其中牛奶在X轴上, 杂货在Y轴上: