知道我们对未知数据进行分类的置信度非常重要. 当新的数据点被分类到已知类别中时, 我们可以训练SVM以计算该输出的置信水平.
怎么做...?
- 全部代码可以在svm_confidence.py文件中找到. 我们这里讨论核心实现方法. 先定义一些数据:
input_datapoints = np.array(
[
[2, 1.5],
[8, 9],
[4.8, 5.2],
[4, 4],
[2.5, 7],
[7.6, 2],
[5.4, 5.9]
]
)
- 计算边界距离:
print ("边界距离:")
for i in input_datapoints:
print (i, '-->', classifier.decision_function(i.reshape(1, -1))[0])
- 输出结果如下:

- 与边界的距离给了我们关于数据点的一些信息, 但它并不能准确地告诉我们分类器对输出标签的可信度. 为此, 我们需要Platt缩放. 这是一种将距离度量转换为类之间的概率度量的方法. 您可以查看以下教程, 了解有关Platt缩放的更多信息: http://fastml.com/classifier-calibration-with-platts-scaling-and-isotonic-regression. 让我们继续使用Platt缩放训练SVM:
# Confidence measure
params = {'kernel': 'rbf', 'probability': True}
# probability 参数告诉SVM它应该训练计算概率
classifier = SVC(**params)
- 训练模型:
classifier.fit(X_train, y_train)
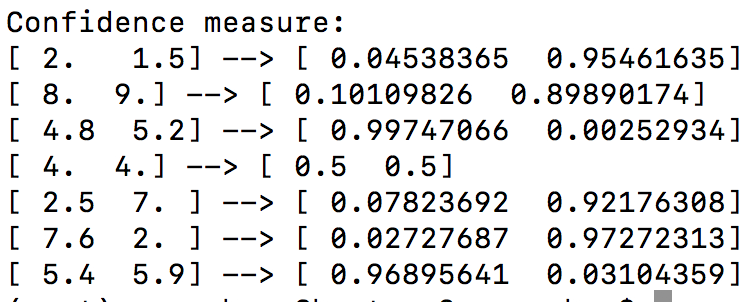
- 让我们计算这些输入数据点的置信度测量值:
print ("\nConfidence measure:")
for i in input_datapoints:
print (i, '-->', classifier.predict_proba(i.reshape(1, -1))[0])
- 结果如下:
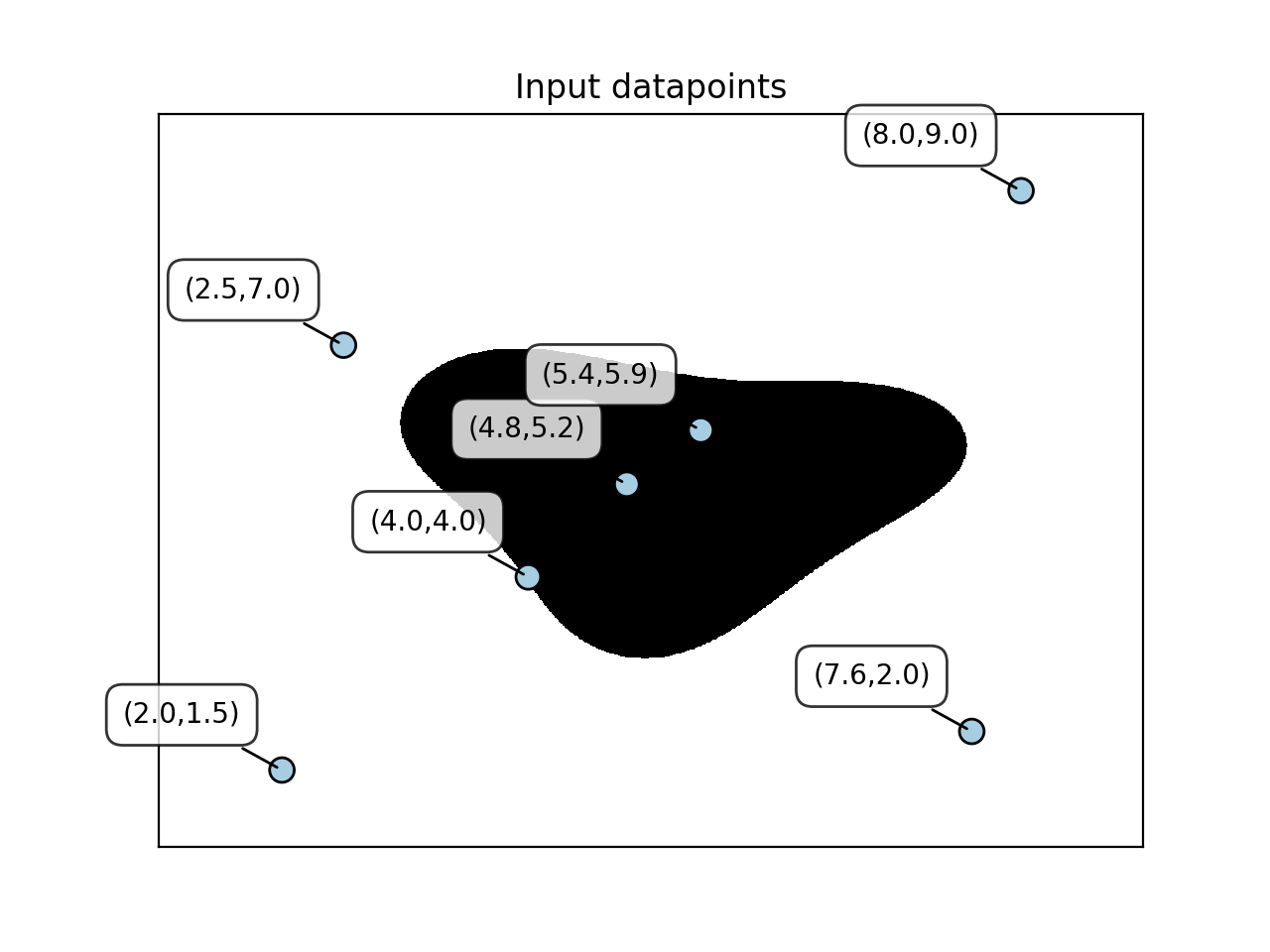
- 让我们看看点相对于边界的位置:
utilities.plot_classifier(
classifier,
input_datapoints,
[0] * len(input_datapoints),
'Input datapoints',
'True'
)
plt.show()
- 结果如下: